Basics of Apache Kafka - An Overview
A few months ago I wrote an article on setting up a local Apache Kafka instance. In this article, I will briefly introduce Apache Kafka and some of its core concepts. We will look at the these concepts from a high level and understand how they are put together.
What is Kafka?
Apache Kafka is an open-source distributed event streaming platform for building real-time data pipelines and streaming applications. It is designed to handle high volumes of data and enable real-time processing of data streams.
Kafka is typically used in scenarios where data needs to be processed in real-time, such as in real-time analytics, event-driven architectures, and other streaming applications. It can be integrated with various systems, such as databases, storage systems, and stream processing frameworks, to support a wide range of use cases.
Event Streaming vs Messages Queues
I have seen people using Kafka interchangeably with message queues. However, they are two things. Kafka is a distributed event streaming system whereas message queuing systems like RabbitMQ, Amazon SQS, and Azure Queue Storage.
I suppose confusion must have stemmed mainly from the fact that the feature sets of these systems are getting more or less the same and the line between them is getting blurred. However, it is advisable to understand trade-offs among these systems and pick one that suits you best without overcomplicating the overall solution.
Why Kafka?
There are several reasons why Apache Kafka is a popular choice for building real-time data pipelines and streaming applications:
- Scalability: Kafka is designed to handle high volumes of data and to scale horizontally, making it suitable for handling large amounts of data.
- Real-time processing: Kafka enables real-time processing of data streams, allowing applications to react to new data as soon as it arrives.
- Fault-tolerant: Kafka is fault-tolerant and highly available, meaning it can continue operating even if some of its components fail.
- Flexibility: Kafka can be integrated with many systems and frameworks, making it a versatile platform for building streaming applications.
- High performance: Kafka has been designed to provide high throughput and low latency, making it suitable for applications that require fast processing of data streams.
In a nutshell, imagine you have the following tightly coupled spaghetti of systems (could be deployed internally within your organization or a public-facing app)
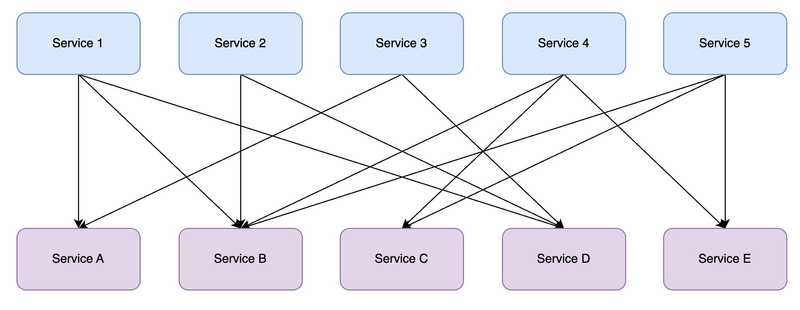
For instance, you could imagine these services to be separate microservices or even monoliths that need to defer their workloads to some other systems. As we can see services 1 - 5 talk to services A - E. This becomes extremely difficult to maintain and will cause massive tech debt.
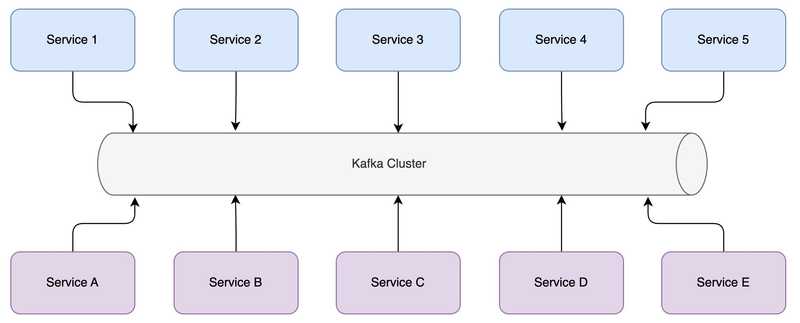
Following is a refactored communication flow utilizing Kafka. Your line of business applications, or microservices can be added or removed as you go. It also provides a consistent API for both produces and consumers. But, could this be a single point of failure? What if Kafka goes down? or can it go down? You’ll find the answers in the upcoming sections, why that’s not the case.
Putting everything together
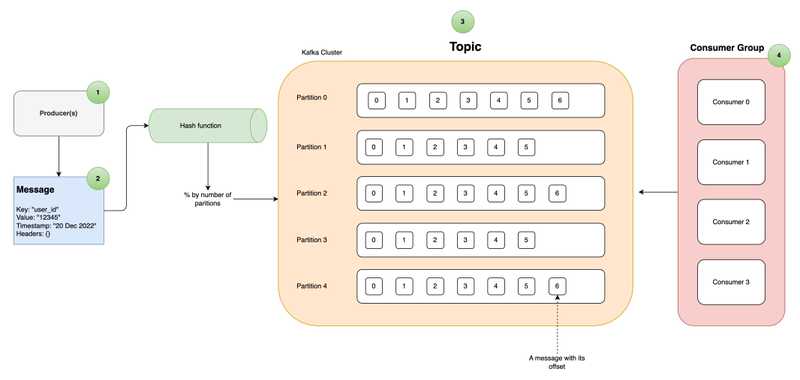
Below is a diagram that I’ve created to show you a typical request flow in Kafka. The numbers correspond to each subheading that I will describe in much detail below. In each section, I will zoom in on a particular concept to provide any relevant context.
Before we jump in, I need to mention that Kafka exposes a client API that could be used by users to write and read messages. You could use your programming language of choice to interact with the cluster using these API calls.
1. Producers
Producers write data (or events) to topics, and consumers read data from topics. Producers could be anything like an IoT sensor, activity tracking system, a frontend server sending metrics etc. You can specify a key/id in your message in order to make sure that the messages always end up in the same partition. More on these will be covered in Events, Topics and Partitions sections.
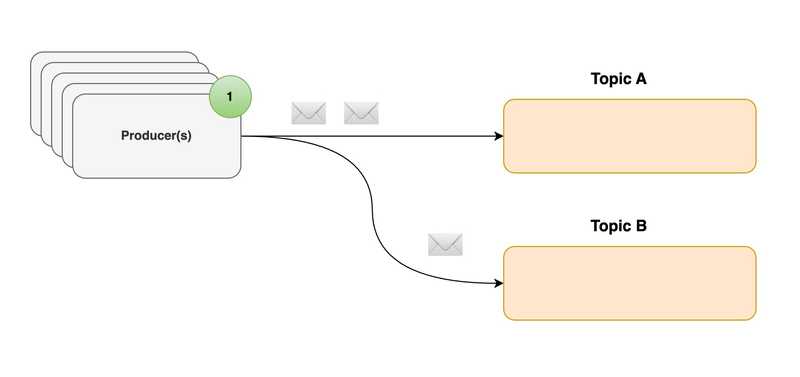
Other than that, it’s worth noting that the Producers can choose 3 methods to send messages (fire and forget, Synchronous send & Asynchronous send) and also they can wait for acknowledgements (none, any or all) as well.
2. Events
An event in Apache Kafka is a record of an occurrence or state change in a system. Sometimes it’s also called a record or a message as well. This could be a user interaction, a change in data, or a notification from another system. Events are stored in Kafka topics and are typically published by producers and consumed by consumers. Events in Kafka are immutable, such that they cannot be changed once they have been published.
Data formats
Kafka sees messages are just byte arrays. However, we humans need a way to serialize and deserialize this data. Therefore, you could use a schema for it such as JSON, Protocol Buffers, or Apache Avro (used in Hadoop).
What’s important to understand is that you use a consistent data format in your applications.
Here is an example of a Kafka event with a key and value that are both strings:
Key: "user_id"
Value: "12345"
Timestamp: "20 Dec 2022"
Headers: {}3. Topics and Partitions
In Kafka, a topic is a way to separate out different messages coming in from different systems. Each topic is partitioned, meaning that the data in a topic is split into multiple partitions distributed across the Kafka cluster. This allows for redundancy and scalability within Kafka.
If a given topic is partitioned across multiple nodes (i.e. servers), how does Kafka know which message goes to which partition also while preserving the order? This is where the key of a message comes in handy. Kafka uses the key of a message and runs it through a hash function and mod (%) the resulting number so that it knows where to write that message.
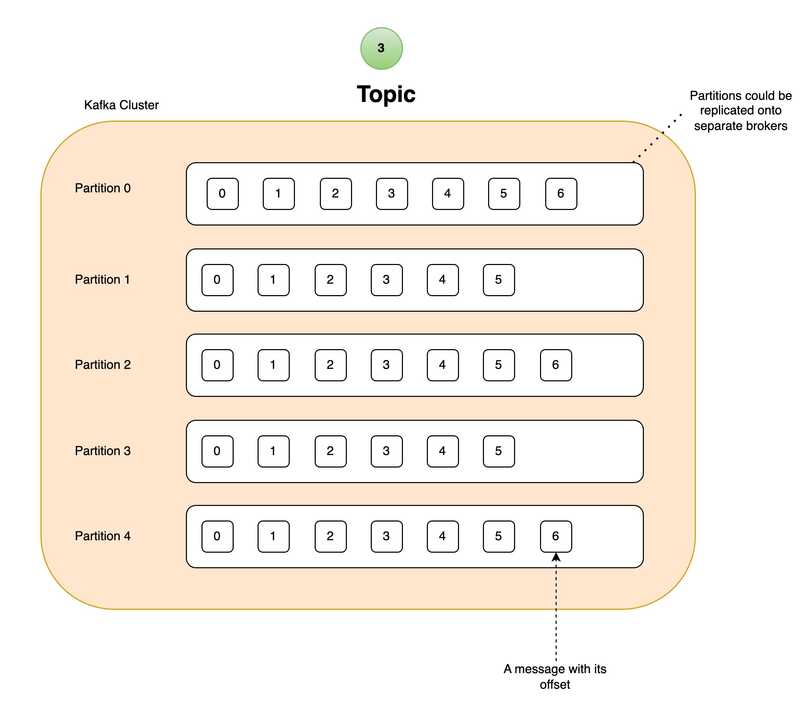
What if a message doesn’t have a key (key being NULL)? Well, in that case, Kafka defaults to a Round-Robin approach to write the messages to the partitions.
💡 Messages with the same key go to the same partition thus guaranteeing the order.
It’s also worth mentioning that a partition is not strictly tied to a single server. They can also scale out horizontally depending on your requirements.
Brokers
if you start working on Kafka, you’d come across the term brokers. A broker is just a computer, server, container, or cloud instance that’s running a Kafka broker process. So what do they do? They are responsible for managing the partitions that we talked about in the previous section. They also handle any read/write requests.
Remember I mentioned that a partition can be replicated across multiple nodes? Brokers manage that replication too. But there has to be some kind of way to orchestrate this replication, right? In Kafka, they follow a leader-follower approach to tackle that. Generally speaking, reading and writing happens at the leader level. Then the leader and followers work among themselves to get the replication done.
4. Consumers & Consumer Groups
The “consumer” is a complex concept in Kafka. Consumers are applications that subscribe to a set of Kafka topics and read from topic partitions. Consumers track their offsets as they progress through topic partitions and periodically commit offsets to Kafka, which ensures that they can resume from the last processed offset in the event of a restart. These offsets are incremental and the brokers will know which messages to send when the consumer requests more data.
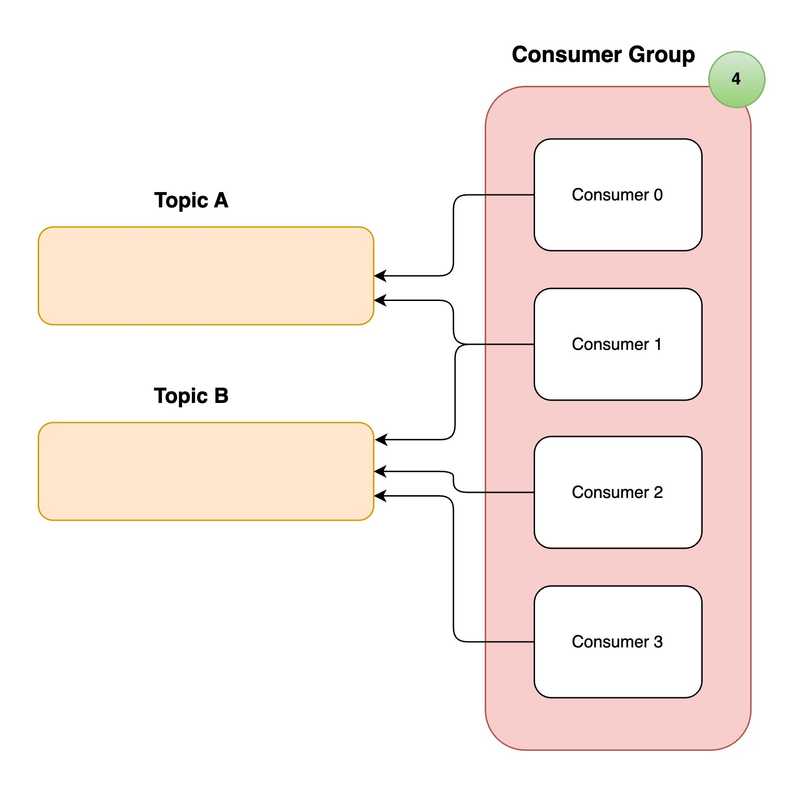
As shown above, same consumer can also listen to mutiple topics as well.
💡 What sets Kafka apart from traditional Message Queues is that reading a message does not destroy it.
Why is Kafka fast?
Apache Kafka uses a combination of in-memory storage and disk storage to achieve high scalability. Kafka stores data in memory in a log structure, which allows for fast access and processing.
However, as the amount of data in a Kafka cluster grows, it can eventually exceed the available memory. In this case, Kafka will automatically flush data to disk to free up memory. This allows Kafka to scale horizontally by adding more nodes to the cluster, which can provide additional memory and disk storage capacity. By combining in-memory and disk storage, Kafka can achieve high scalability while still providing fast access and processing of data.
How do I build a Kafka cluster?
If your organization has a need to deploy your own cluster at a data center you can do that. Kafka’s deployment targets range from bare metal servers to cloud providers. If you are rolling out your own, beware that it’s not easy to set it up it will take time.
Locally (Development)
- Using Docker is the easiest I’ve found. Follow this guide to understand how you can do that.
- Or you could YOLO and install the binaries yourself 😀
Cloud (Production)
For your production needs, your best bet would be to use
Different cloud providers might charge you differently. It’s always wise to consider the pricing options before locking yourself into a specific cloud provider.
Conclusion
In this article we looked at Apache Kafka is an open-source distributed event streaming platform for building real-time data pipelines and streaming applications. We went over the main concepts that should be enough to get you started. I’m planning to write an article series on implementing producers and consumers in .NET, Go & Python. So stay tuned! Until next time 👋